
for-async-loop on nodejs streams
New versions of JavaScript and version 12 of nodejs have made a great feature available, that is also making me to re implement one of my best node modules. This time I am talking about the ‘for await’ loop and nodejs streams support for asynchronous generators.
One after an other. Streams are the needed structure in code, when you need to handle more data than you can fit into memory at once. You have a machine with 16gb of RAM? To process a file bigger than that efficient, we need a way to process chunk after chunk. When developing a stream, with multiple steps, it is important to keep the different speeds working together. Loading a file from disk, for example from a backup, can be very fast, compared to inserting the data into the database somewhere on the network, that need to build indexes and more.
With version 12 of nodejs, streams and for await loops work together very well. Here is my example for importing the planet data of open street map into db, I found the db slower then reading the file stream.
1 | const bz2 = require('unbzip2-stream'); |
In this code, you see first the imports, the configuration for processing the planet file, followed by the main function. In the bottom we have the two utility functions get and sleep. Within the main function, we create a read stream, that is directly downloading from the remote server, provided by the open street map project. Just for some statistics we add a on ‘data’ event to that download stream that is directly unzipped.
Next we pipe the text stream into the XML transformStream. Using the for await loop, we can process one item at a time. using some more logic we could easily make chunks of nodes to process more nodes at once, for inserting many items with a single INSERT statement to SQL for example. The loop sleep a little to simulate a slow database here and also maintain some statistics.
Now lets take a look at the output.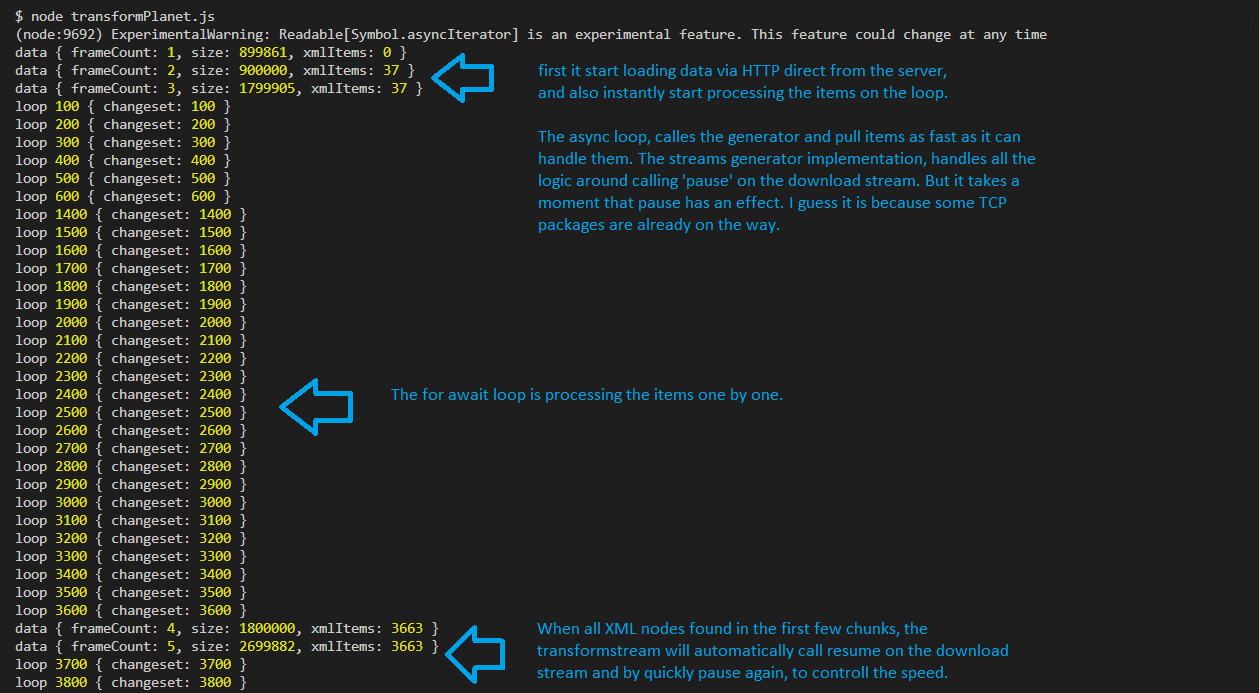
This shows that we can control the speed of the entire stream just by using a for loop. I thinks this is a great step for building scalable applications with very clean code. It is really awesome, that it is possible to process the data, without downloading the entire planet file upfront. What do you think?
By the way, to implement the transformStream for xml, I used the through2 module, it was very easy to change the implementation from the existing “event” based implementation to this stream support.